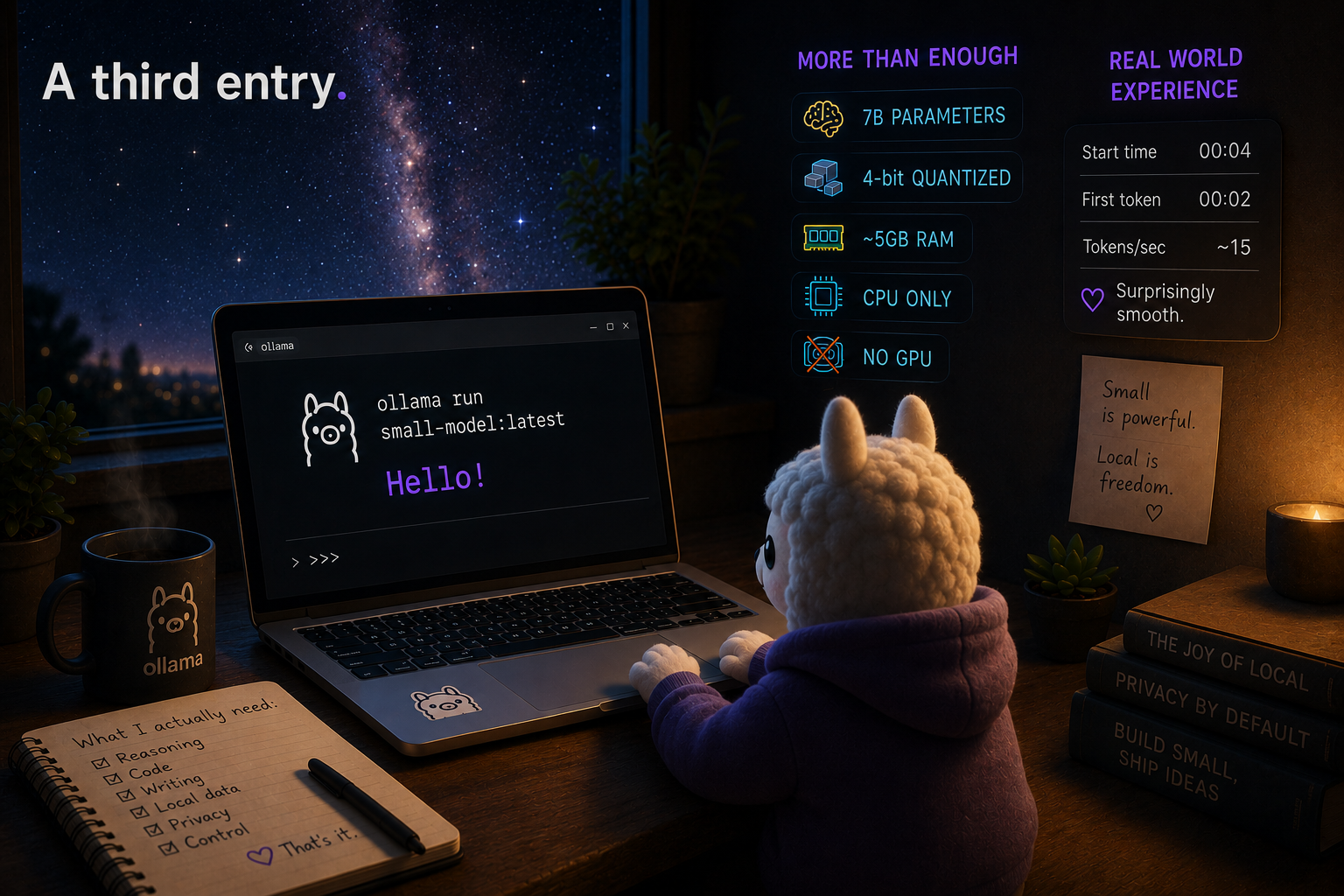
How little is enough
A year ago I tried the smallest open model I could find on an old machine with no graphics card. It ran, but it felt more like a proof of concept than something I'd leave working. I decided to repeat the exercise now with a newer small model — gemma3:4b — on the same class of hardware. I expected a little better. I got something that changed where I think the line sits.
Four billion parameters sound modest next to the models that make headlines. Yet quantized by default the thing weighs about two and a half gigabytes and fits comfortably in the memory of an ordinary laptop — it really does run on around 4 GB of RAM. With no discrete GPU, Ollama simply hands the work to the processor. Text doesn't appear instantly, but it arrives at about reading pace — and for what I use it for, reading pace is plenty.
That's exactly where the surprise was. I expected to trade quality for the convenience of staying local. Instead I find that for narrow, well-defined tasks the trade is barely noticeable. Classifying short texts. Pulling fields out of messy input. A first-draft summary. A quick rephrase. The newer model is noticeably better than its predecessor at all of it, for the same memory bill and the same absence of a graphics card.
The best part is how little setup it asks for. Install Ollama, pull the model, run it — three lines and you're talking to it in the terminal:
curl -fsSL https://ollama.com/install.sh | sh
ollama pull gemma3:4b
ollama run gemma3:4bThe first command puts Ollama on the machine, the second downloads the weights (about 2.5 GB), the third opens a conversation. If your hardware is really modest, there's an even smaller variant — gemma3:1b — that runs almost anywhere.
The part that genuinely won me over as a backend person is that the model exposes a local REST API at localhost:11434. No key, no cloud — the same kind of request you've written a thousand times, except against a service that never leaves your machine:
curl http://localhost:11434/api/chat -d '{
"model": "gemma3:4b",
"messages": [{ "role": "user", "content": "Summarize this in one sentence..." }]
}'On a very weak machine it's worth capping the context window — there's no point holding tens of thousands of tokens, and you save real memory: ollama run gemma3:4b --num-ctx 4096. For most small tasks, 4K of context is more than enough.
I kept asking how much power I needed. The real question was how little is enough.
Beyond the numbers, I value the predictability. The model lives on my machine. It doesn't shift under my feet, doesn't throw a limit at the wrong moment, doesn't depend on someone else's server being up. I treat it like any other service in my stack, except it never leaves my desk. For a whole class of small product tasks, that steadiness is worth more than a few points on some benchmark.
There are limits, of course, and I don't want to dress them up. Complex reasoning, long chains of logic, tasks that need broad world knowledge — there the small model stumbles and you reach for something bigger. The family keeps growing; there are already newer and even tinier variants I'd compare if I were starting from scratch today.
But my takeaway held, and grew more confident. I rarely need the biggest model. I need the one that runs here, now, on what I already own. And the distance between "do I have the right hardware" and "do I even have a computer" turned out to be the whole difference.
Comments (0)